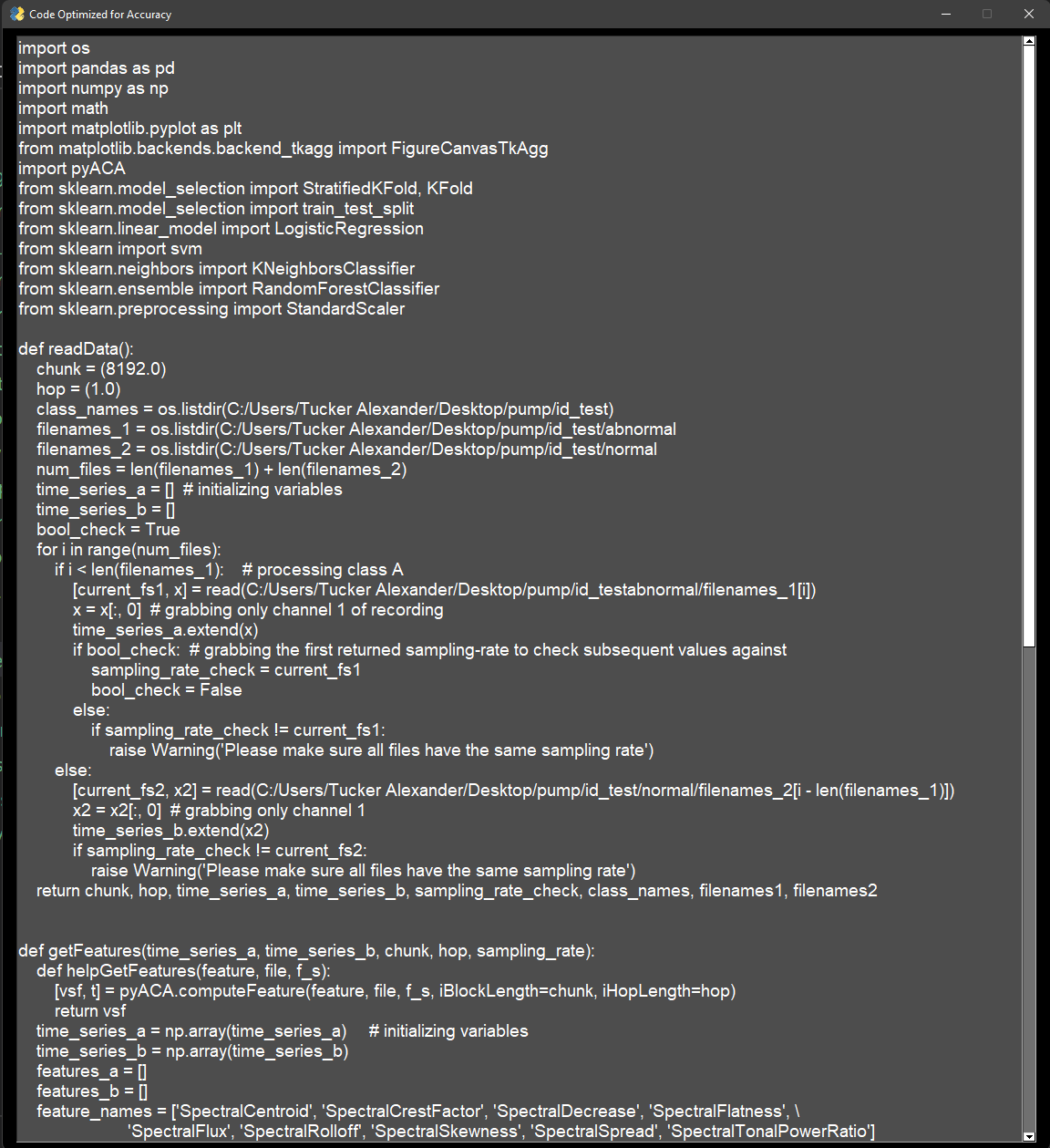
Audio Classification Tool
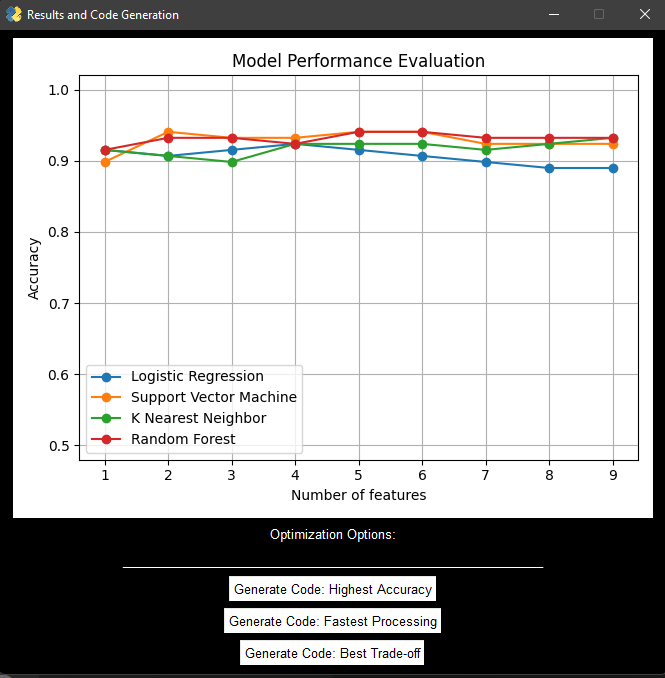
This project allows a user to train a machine learning model to categorize audio files without writing any code. The process works for any audio dataset. The application automatically parses the audio files into equally sized chunks, extracts meaningful information (audio features) from each chunk, trains a selection of machine learning models on this generated data, and compares the accuracy of each model. The optimization algorithm looks at three potential scenarios and allows the user to select their desired output. These scenarios are: highest overall accuracy, fastest computation time, and a tradeoff between accuracy / efficiency. Upon selecting one of these scenarios, immediately executable code snippets are generated which the user can then use to categorize data collected in the future.
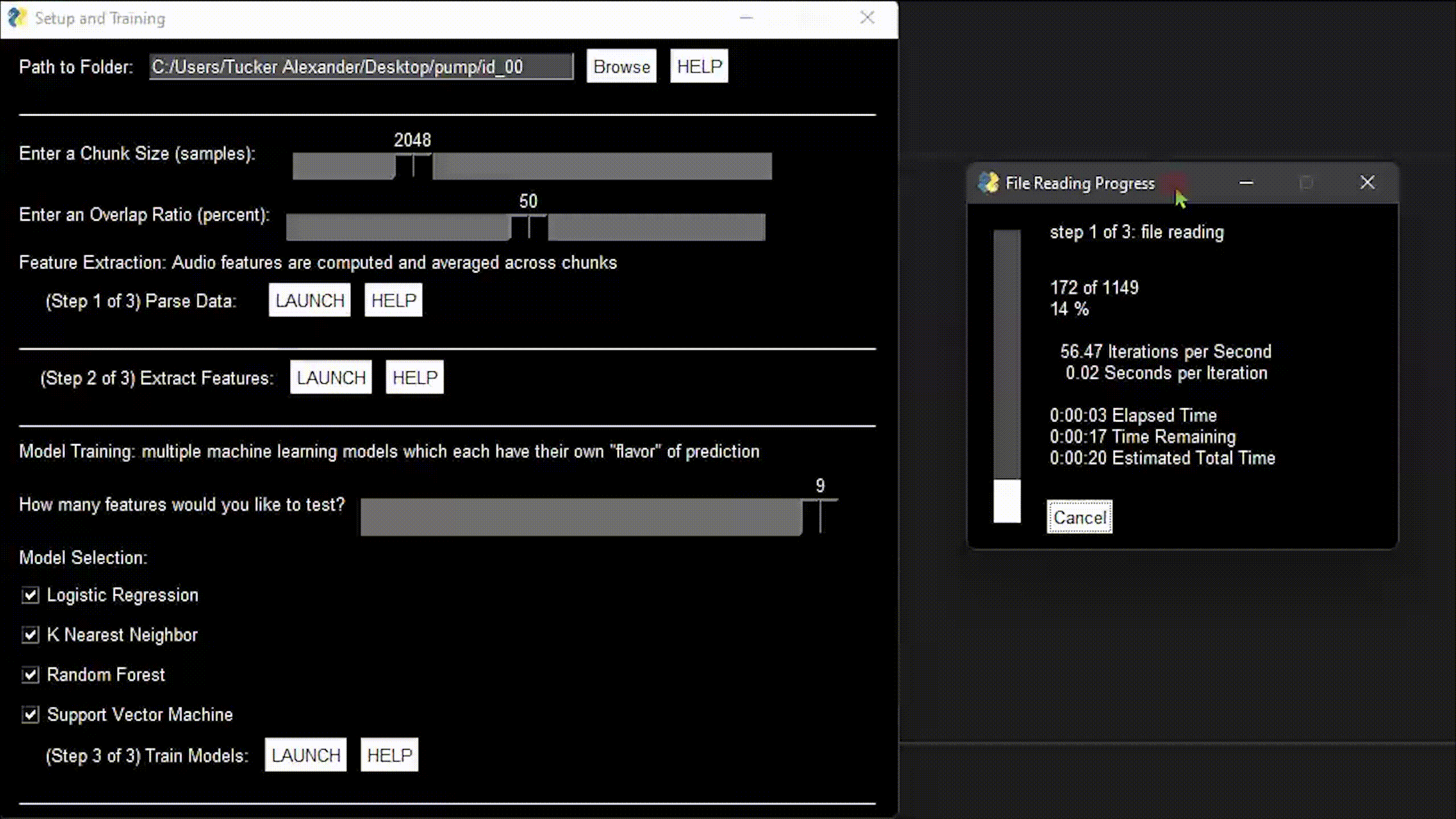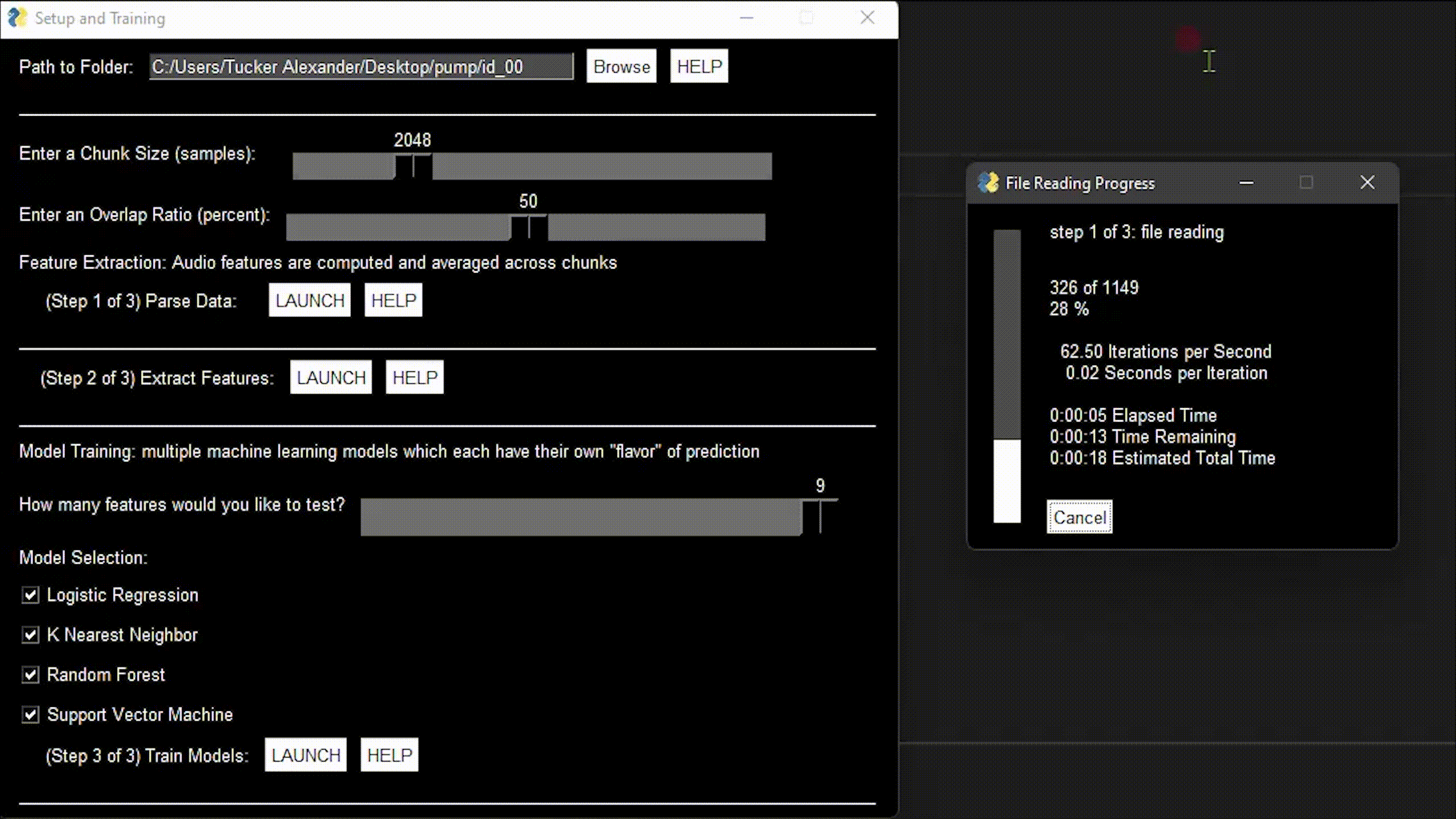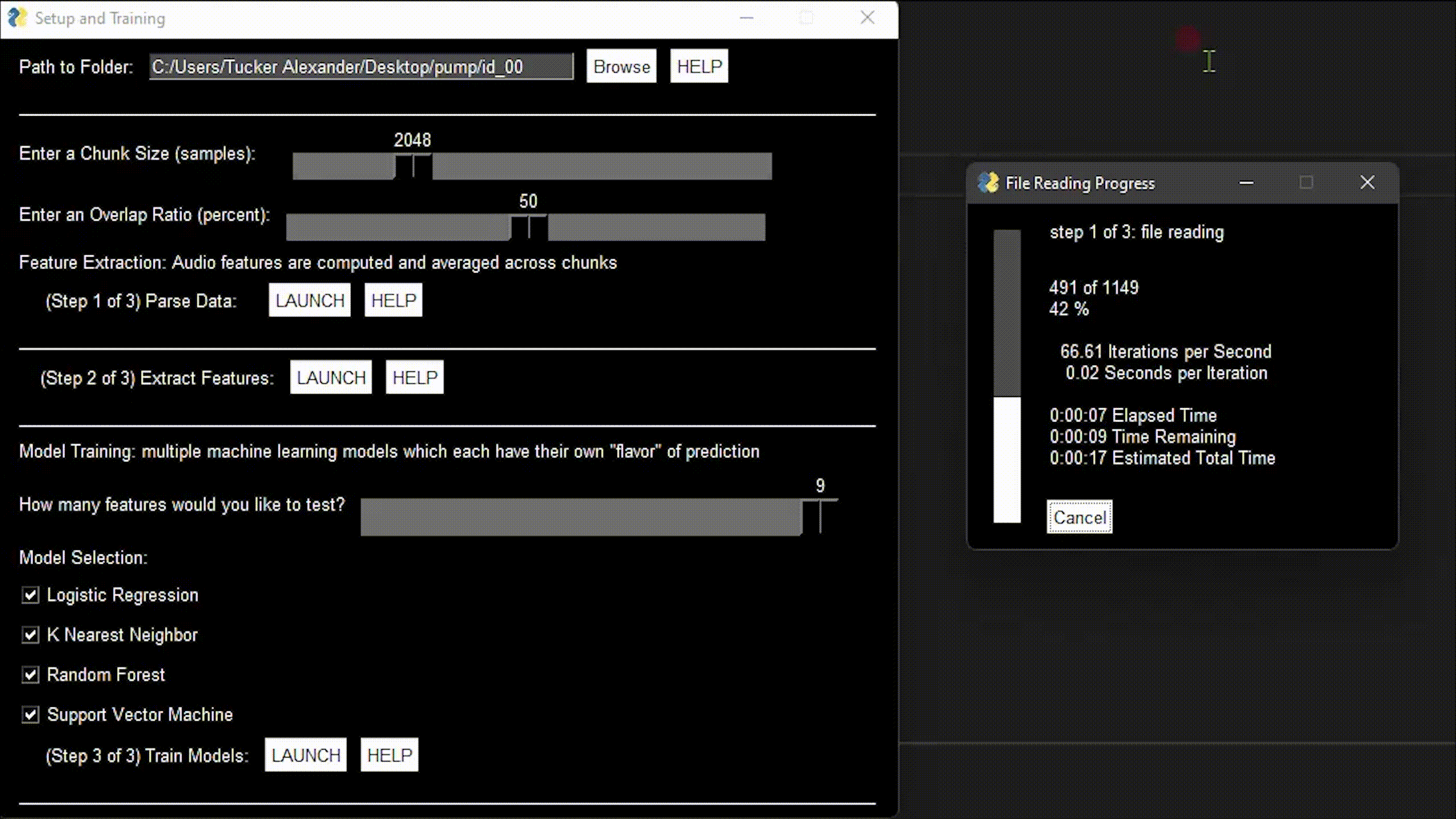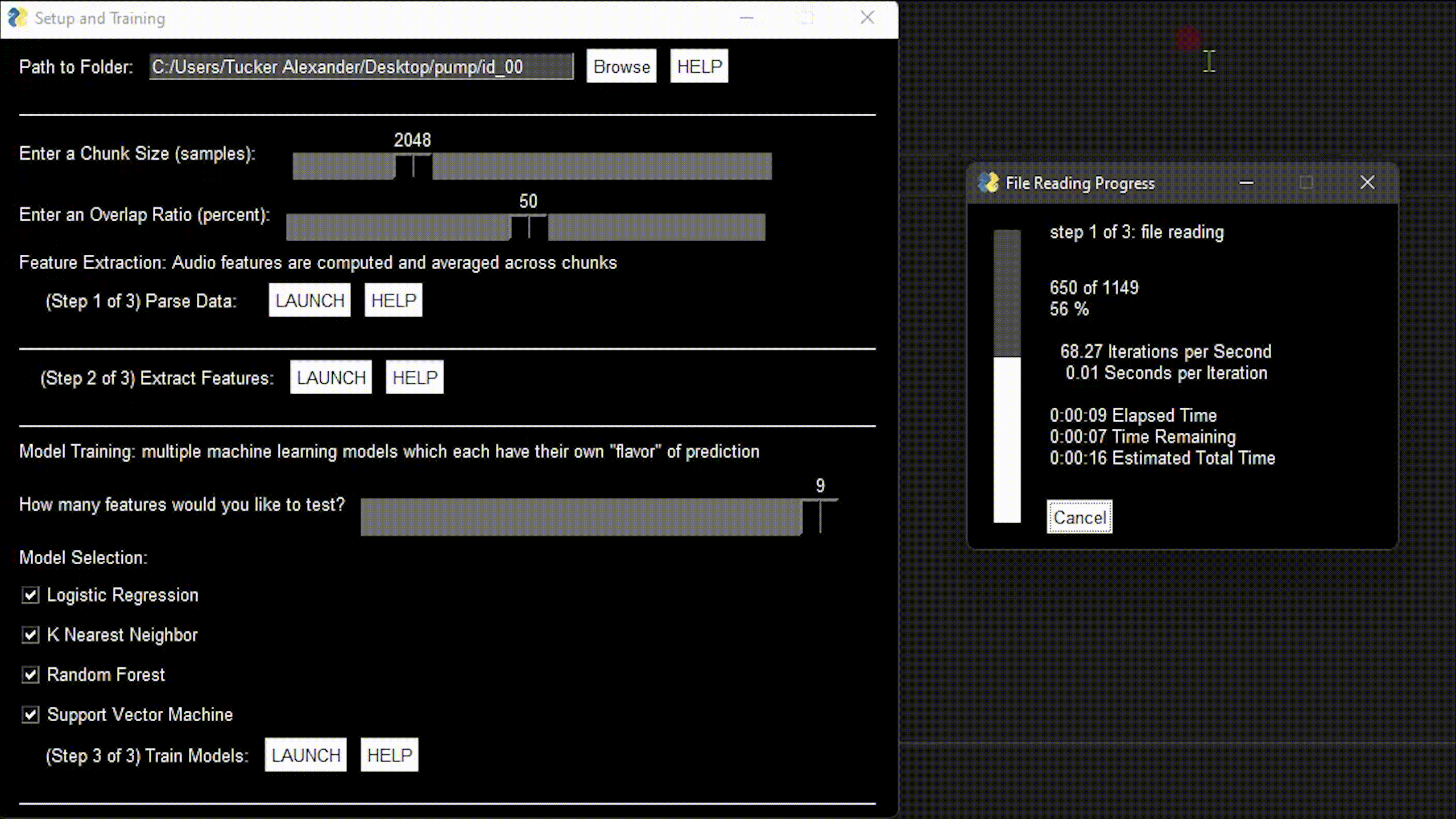
Landing Page
Results Page
Example of Generated Code